
JOIN이란?
두개이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법
논리적 조인과 물리적 조인으로 나뉜다.
논리적 조인

1. INNER JOIN
- 기준테이블과 Join한 테이블의 중복된 값을 보여줌
- 교집합
2. LEFT OUTER JOIN
- JOIN 문 기준 왼쪽 테이블(A)의 전체 데이터와, A테이블과 B테이블의 중복 데이터를 보여줌
3.RIGHT OUTER JOIN
- JOIN문 기준 오른쪽 테이블(B)의 전체 데이터와, A테이블과 B테이블의 중복 데이터를 보여줌
4.FULL OUTER JOIN
- A테이블과 B테이블 데이터 모두를 보여줌( 사실상 모든 데이터 출력)
- 합집합
5. CROSS JOIN
- 모든 경우의 수를 표현해줌
- 기준 테이블이 A일 경우, A 데이터의 ROW를 B테이블 전체와 JOIN하는 방식
- 결과값은 A 레코드 수 * B 레코드 수
6. SELFT JOIN
- 자기 자신과 자기 자신을 조인
- 1개의 테이블(X)에 가상으로 x1, x2라는 별칭을 부여하여 2개의 테이블인 것처럼 간주한 뒤 JOIN
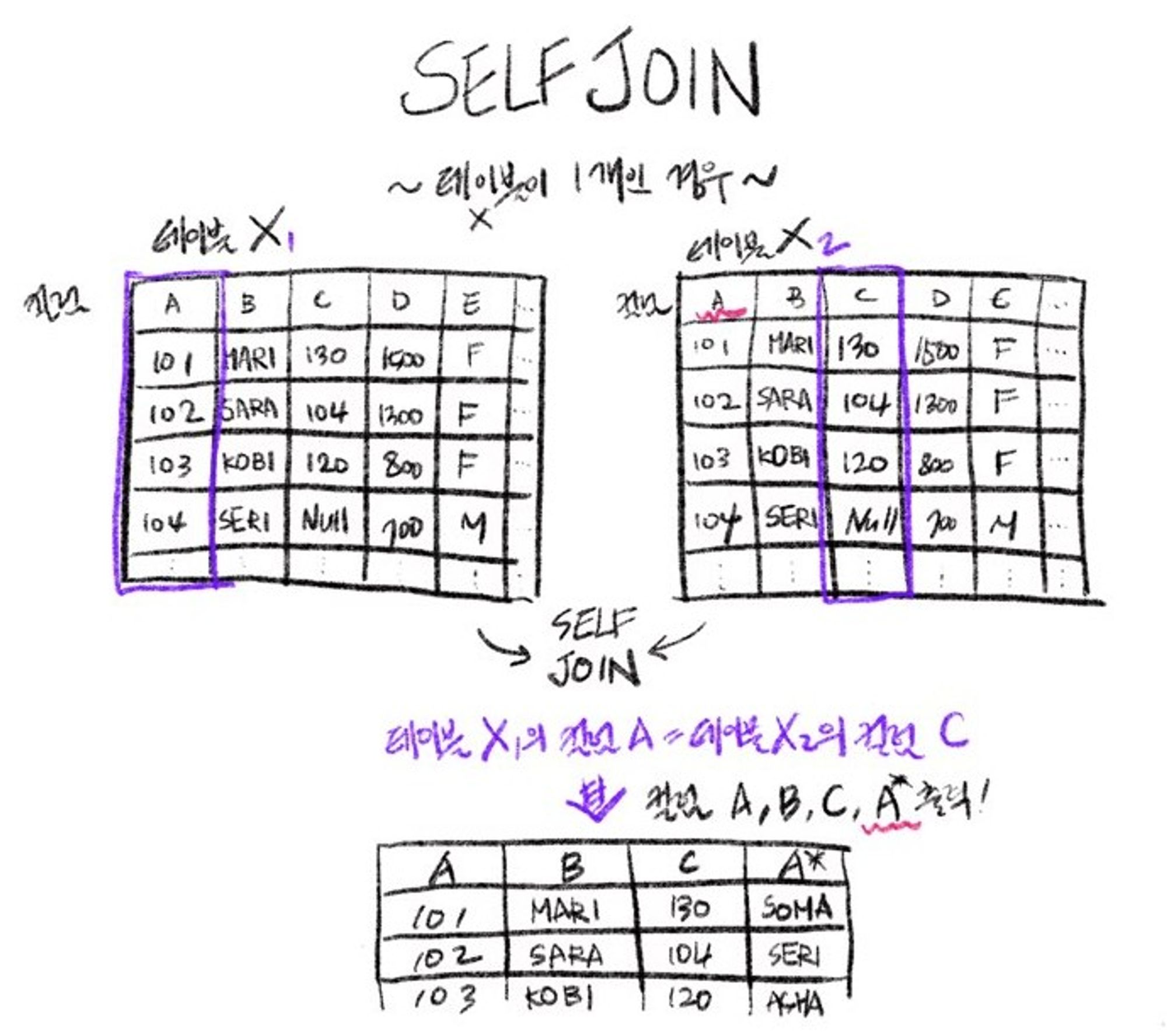
각 구성원들 간에 멘토-멘티 관계가 있다고 가정할 경우
A - 멘토의 구성원 번호
B - 멘토 성명
C - 멘티의 구성원 번호
이 구성원 테이블을 A컬럼과 C컬럼을 기준으로 SELF JOIN 하여, 멘토 번호-멘토 성명-멘티 번호-멘티 성명을 한 화면에서 조회할 수 있게 된다.
물리적 조인
1. Nested Loop Join ( 중첩 반복 조인 )

- 2개 이상 테이블에서 하나의 테이블을 기준으로 순차적으로 상대방 ROW를 결합하여 원하는 결과를 추출하는 방식
- Driving Table의 처리 범위를 하나씩 액세스 하면서 추출된 값으로 Driven Table을 조인하는 방식으로 동작
( 바깥 테이블의 처리 범위를 하나씩 접근하면서 추출된 값으로 테이블을 조인하는 방식)
- NL 조인은 두 테이블이 조인을 할 때, 드라이빙 테이블( Outer 테이블)에서 결합 조건에 일치하는 레코드를 내부 테이블(Inner Table)에서 조인하는 방식
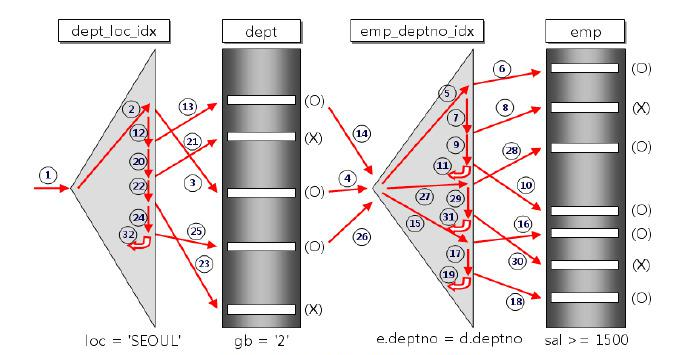
NESTED LOOP JOIN의 동작 방식은 위의 그림과 같고 동작 순서는 번호 순대로 진행
for(i=0; i<dept.length; i++) { -- driving table
for(j=0; j<emp.length; j++) { -- driven table
// Search
}
}이중 for문과 작동원리가 비슷하다.
위의 그림에서 먼저 액세스 된 dept Table이 Driving Table이고 나중에 액세스 된 emp Table이 Driven Table
dept의 데이터를 추출하기 위해 dept_loc_idx라는 인덱스를 사용하여 gb = '2'인 데이터를 추출하였으며, 이렇게 검색된 데이터를 가지고 같은 deptno를 가지는 사원들의 정보를 emp_deptno_idx라는 인덱스를 사용하여 sal >=1500 조건으로 emp Table을 조회.
이렇듯 NESTED LOOP JOIN의 동작 방식은 Driving Table의 처리 범위를 하나씩 액세스 하면서 추출된 값으로 Driven Table을 조인하는 방식으로 동작
SELECT /*+ USE_NL (B) */
A.*
, B.*
FROM ITEM A
,UITEM B
WHERE A.ITEM_ID=B.ITEM_ID --- 1
AND A.ITEM_TYPE_CD = '100100' --- 2
AND A.SALE_YN = 'Y' --- 3
AND B.SALE_YN = 'Y' --- 4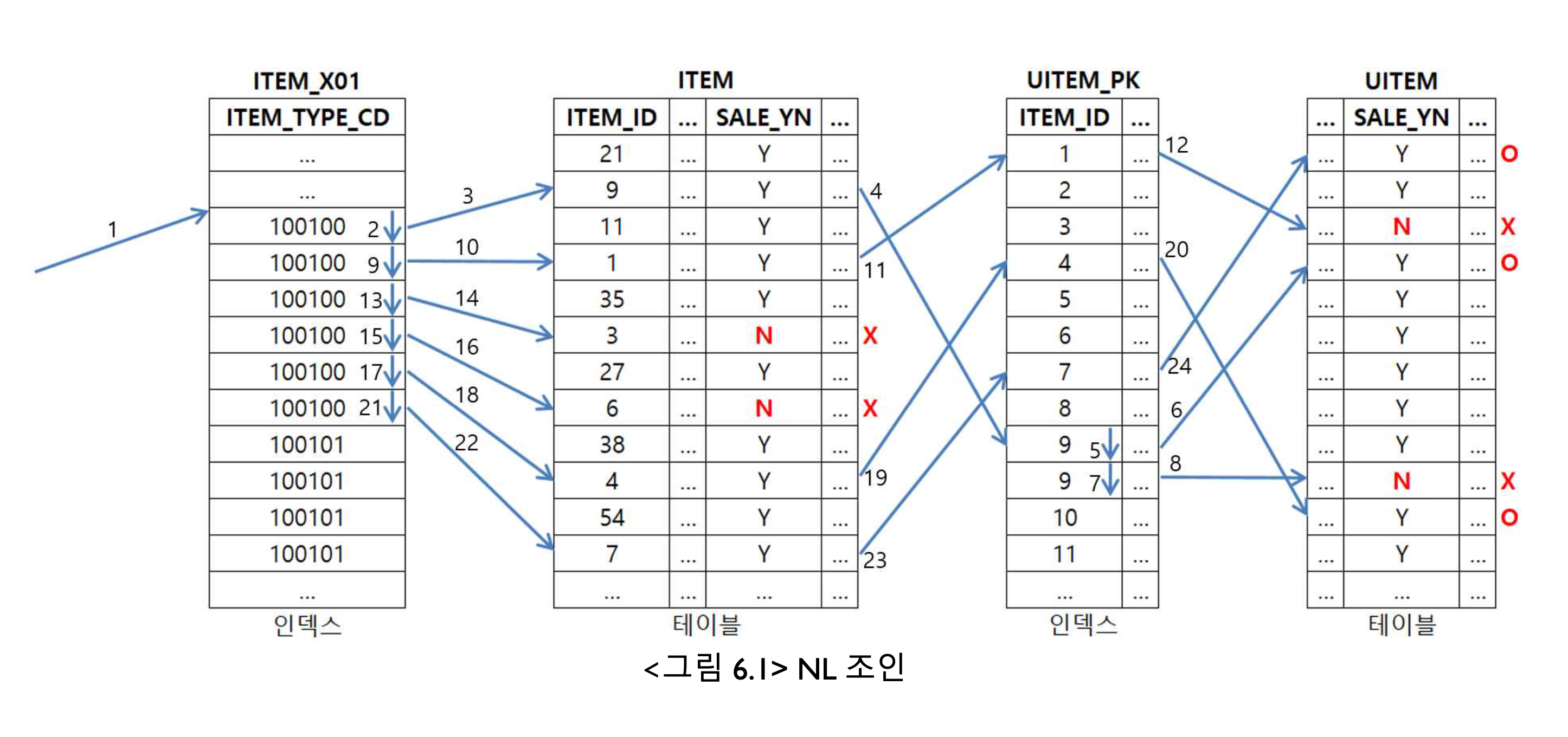
기준 테이블 ( Driving Table) : ITEM , Inner 테이블 : UITEM
실행 순서
인덱스 ITEM_X01를 통해 ITEM_TYPE_CD = 100100인 것을 스캔힌다.
인덱스 ITEM_X01에서 읽은 rowid를 가지고 A 테이블에 액세스해 SALE_YN = 'Y' 인 필터 조건을 만족하는 레코드를 찾는다.
A 테이블에서 읽은 ITEM_ID와 같은 값을 가진 B 테이블의 ITEM_ID를 찾기 위해 UITEM_PK를 스캔한다.
B 테이블에 액세스하여 SALE_YN = 'Y' 인 레코드들을 찾는다.
특징
- 선행 테이블의 결과를 통해 후행 테이블을 액세스 할 때 랜덤 I/O가 발생한다. (두 테이블의 랜덤 I/O가 높게 나옴)
- 인덱스에 의한 랜덤 액세스에 기반하므로, 대량 데이터 처리 시 적합하지 않다.
- 메모리 사용량이 가장 적다.
- 순차적으로 처리한다.
- 순차적으로 처리하기 때문에 안쪽 테이블에 인덱스가 필요하다.
- MySQL 에서는 오랫동안 NL 조인만 지원하고 있었다. ( 최근 MySQL 8.0.18 버전부터는 해시 조인도 지원한다.)
해당 조인을 사용하는 경우
- 한쪽 입력이 작고(Driving Table), 다른 한쪽 입력이 크면서 join열에 인덱스가 있는 경우(Driven Table)
- I/O 연산과 비교 연산이 가장 적게 필요하기 때문
cf) Driving / Driven Table이란
- 선행 테이블(Driving Table) : 조인 시 먼저 액세스 되는 테이블. WHERE 절로 최대한 데이터를 거를 수 있는 테이블 / 데이터 양이 적은 테이블로 선정
- 후행 테이블(Driven Table) : 조인 시 나중에 액세스 되는 테이블 (Driving이 아닌 나머지 테이블). 조인을 위한 인덱스가 생성되어 있는 것이 좋다 (없다면 Driving Table에서 도출된 결과와 맞는지 매번 FULL TABLE SCAN으로 일일이 비교해야 하기 때문)
2. Merge Join / Sort Merge Join ( 정렬 병합)

- 양 테이블을 각각 접근하여 결과를 정렬하고, 정렬한 결과를 Scan해가면서 연결 조건으로 Merge하는 방식
- 소트머지 조인은 두 테이블을 각각 조건에 맞게 먼저 읽는다. 그리고 읽은 두 테이블을 조인 컬럼을 기준으로 정렬해놓고, 조인을 수행한다. 주로 조인 조건 칼럼에 인덱스가 없거나, 출력해야 할 결과 값이 많을 때 사용된다.
NL 조인을 효과적으로 수행하려면 조인 컬럼에 인덱스가 필요한데 만약 적절한 인덱스가 없다면 Inner 테이블을 탐색할 때마다 반복적으로 Full Scan을 수행하므로 매우 비효율적이므로 그럴 때 옵티마이저는 소트 머지 조인이나 해시 조인을 고려한다.
오라클에서는 정렬을 하게 되면 PGA라는 공간에서 정렬을 수행하게 되는데, PGA 공간은 프로세스에 할당 된 독립된 공간이기 때문에 버퍼 캐시(SGA영역)를 사용하는 NL 조인에 비해 조인을 시도하는 데이터 접근이 보다 빠르게 수행된다.
SELECT /*+ ORDERED USE_MERGE(B) */
A.*
, B.*
FROM ITEM A
,UITEM B
WHERE A.ITEM_ID=B.ITEM_ID -- 1
AND A.ITEM_TYPE_CD = '100101' -- 2
AND A.SALE_YN = 'Y' -- 3
AND B.SALE_YN = 'Y' -- 4
ITEM_X01 -> ITEM_TYPE_CD UITEM -> 없음동작 순서
2 -> 3 -> 4 -> 1

실행 순서
A 테이블에서 인덱스 ITEM_X01를 통해 ITEM_TYPE_CD = 100100인 것을 스캔하고 SALE_YN = 'Y'인 필터조건을 맞는 데이터를 찾는다.
B 테이블에서 SALE_YN = 'Y' 에 해당하는 데이터를 찾기 위해 Table Full Scan으로 읽는다.
PGA 공간에서 조인컬럼을 기준으로 정렬을 수행한다.
두 테이블을 조인한다.
cf) Table full scan : 전체 테이블을 첫번째 블록부터 차례대로 스캔하여 조건을 만족하는 데이터 블록을 엑세스하는 방식
특징
- 동시 처리 ( 양 테이블을 동시에 읽고 양 테이블이 join 준비가 되었을 때 join 수행 )
- 독립적 ( 처리 범위를 줄일 수 있는 수단은 각 테이블의 while 조건 )
- 인덱스 유무는 중요하지X ( 정렬된 양쪽 결과를 스캔하는 방식이므로)
- 정렬에 따라 메모리 사용량이 증가
- 스캔위주의 액세스방식을 사용
동작 방식
1. 각 테이블에 대해 동시에 독립적으로 데이터를 먼저 읽어 들인다.
2. 읽혀진 각 테이블의 데이터를 조인을 위한 연결고리에 대하여 정렬을 수행한다.
3. 정렬이 모두 끝난 후에 조인 작업이 수행한다.
해당 조인을 사용하는 경우
1. 두 join 열을 미리 정렬된 상태로 가져올 수 있는 경우
2. 연결 고리에 인덱스가 전혀 없는 경우
3. 대용량의 자료를 조인할때 유리한 경우
4. 조인 조건으로 <, >, <=, >=와 같은 범위 비교 연산자가 사용된 경우
5. 인덱스 사용에 따른 랜덤 액세스의 오버헤드가 많은 경우
( 두 입력의 크기가 서로 비슷할 경우에는 Merge Join과 Hash Join 성능이 비슷하지만, 두 입력의 크기가 서로 많이 다를 경우 Hash Join 성능이 더 좋다.)
cf) 두 결과 집합의 크기가 많이 차이나는 경우에는 SORT MERGE JOIN이 비효율적이다.
어느 한 쪽이라도 정렬 작업이 종료되지 않으면 조인이 시작될 수 없으므로 두 테이블 조인 집합의 크기가 많이 차이가 난다면 한쪽에 '대기' 상태가 발생하여 비효율적으로 처리가 된다. 이렇게 크기가 비슷하지 않은 집합의 조인을 위해서 HASH 조인을 사용할 수 있다.
성능 개선 방법
- 양쪽 테이블을 Access하는 과정에서 적절한 Scan을 사용하여 Access 속도를 빠르게 해준다.(적절한 Scan 사용)
- 양쪽 테이블에서 조인 컬럼이 이미 정렬되어있다면 속도가 향상됨
- 두 테이블 ACCESS속도와 정렬 속도를 최대한 비슷하게 맞춘다 ( 양쪽 테이블을 ACCESS하고 조회한 데이터들을 정렬할때 어느 한쪽이라도 정렬 작업이 종료되지 않으면 조인이 시작되지 않는다)
- SORT_AREA_SIZE를 적당한 크기로 최적화 시킨다( SORT_AREA_SIZE란 두 테이블이 정렬 작업을 위해 사용되는 정렬 공간에서 할당받을 수 있는 메모리 사이즈. 만약 이 사이즈가 부족하다면 Temporary Table Space를 사용하게 되면서 딜레이가 생김)
3. HASH JOIN

- 두 테이블 중 하나를 Hash Table로 선정하여, 테이블의 key 값을 Hash 알고리즘으로 비교하여 조인을 수행하는 방식
- Sort-Merge 조인은 소트의 부하가 많이 발생하여, 이를 보완하기 위한 방법으로 Sort 대신 해쉬값을 이용하는 조인
- Build Input을 읽어 해쉬 영역(Hash Area)에 해쉬 테이블(=해쉬 맵)을 생성하고, Probe Input을 읽어 해쉬 테이블을 탐색하면서 조인하는 방식
- HASH JOIN은 비용 기반 옵티마이저를 사용할 때만 사용될 수 있는 조인 방식이며 '=' 비교를 통한 조인에서만 사용될 수 있습니다. 주로 많은 양의 데이터를 조인해야 하는 경우에 주로 사용된다.
cf) build input : 작은 쪽 probe input : 큰 쪽
동작 방식
- 둘 중 작은 집합(Build Input)을 읽어 해쉬 영역(Hash Area)에 해시 테이블(또는 Hash Map)을 생성
(해시 함수에서 리턴 받은 버킷 주소로 찾아가 해시 체인에 엔트리를 연결)
- 반대쪽 큰 집합(Probe Input)을 읽어 해시 테이블을 탐색하면서 JOIN
- 해시 함수에서 리턴 받은 버킷 주소로 찾아가 해시 체인을 스캔하면서 데이터를 찾는다.
사용되는 경우
1. JOIN 컬럼에 적당한 인덱스가 없어 NL JOIN이 비효율적일 때
2. JOIN Access량이 많아 Random Access 부하가 심하여 NL JOIN이 비효율적일 때
3. join 입력 크기가 크고, 정렬되지 않았을 때 (대용량 데이터를 조인할 때)
4. 수행빈도가 낮고 쿼리 수행 시간이 오래 걸리는 대용량 테이블을 JOIN 할 때
5. '=' 비교를 수행할 때
6. 집합 일치 연산'(inner/outer/semi join, intersection, union, difference 등), '중복 제거', '그룹핑'
7. 비용 기반 옵티마이저를 사용할 때
성능 개선 방법
1. HASH TABLE을 만드는 과정을 효율화 : Build Input이 Hash Area에 담길 정도로 충분히 작아야 하며 Build Input 해시 키 칼럼에 중복 값이 거의 없어야 좋다.
2. CPU 성능 향상 : HASH BUCKET이 조인 집합에 구성되어 해시 함수 결과를 저장해야 하는데 기본적으로 HASH_AREA_SIZE에 지정된 크기만큼의 메모리가 할당되어 사용됨. 이 과정에서 CPU 와 많은 메모리를 소모하므로 CPU를 향상 시킬 것
3. 충분한 PGA 메모리 확보 : Hash Area는 PGA 메모리에 할당되는데 Build Input이 HASH_AREA_SIZE를 초과하게 되면 가장 큰 순서대로 Hash Bucket이 Temporary Table Space로 내려가서 구성됨. 디스크로 내려간 Hash Bucket에 변경이 일어날 때마다 디스크 I/O가 발생하게 되어 성능이 현저하게 저하됨
등가 조인과 비등가 조인
등가조인(Equi Join)
- 흔히 사용하는 조인의 형태
- 조건 절에 조인되는 두 테이블의 컬럼을 Equal 연산자(=)로 연결하는 경우
- 주로 Primary Key와 Foreign Key 컬럼이 서로 조인될 때 이용되는 형태 입니다.
비등가조인(Non-Equi Join)
- 조인 조건이 Equal 연산자 이외의 >, >=, <, <=, <>, BETWEEN … AND 연산자들을 이용하여 조인을 하는 경우
- 한 테이블의 어떠한 컬럼도 조인 할 테이블의 컬럼에 직접적으로 일치하지 않는 경우에 사용
- 내부조인 이라고도 한다.
select g.gname, g.point, gi.gname from gogak g
inner join gift gi on g.point between gi.g_start and gi.g_end;
cf) ANSI 조인과 ORACLE 조인
-- ANSI
select s.studno, s.name, d.dname from student s
inner join department d
on s.deptno1 = d.deptno;
--ORACLE
select s.studno, s.name, d.dname from student s, department d
where s.deptno1 = d.deptno;
참고
https://hyeyul-k.tistory.com/14