
깃허브 링크 : https://github.com/ankisile/Youtube-data-api-with-playlistItems
YOUTUBE의 채널 URL를 이용하여 특정 시점이후의 동영상을 엑셀에 받아오는 프로그램을 작성해 볼것이다.
어떤 리소스를 쓸지는 youtube data api 레퍼런스 문서를 보면된다.
https://developers.google.com/youtube/v3
킹갓 구글님들은 youtube와 관련된 웬만한 api들을 제공해준다.
따라서 search 를 사용해 볼것이다.
search는 검색 매개변수와 관련된 동영상들을 리턴해준다.
1. Youtube 채널 id 구하기
우리는 채널의 url을 알고 있으나 채널 아이디는 알고 있지 않다.
채널 url은 다음 세가지 형태로 나타나진다.
https://www.youtube.com/channel/UCEK4qLAKncRumkuqfWUbMgQ/videos
첫번째 url 같은 경우 /channel/ 뒤의 string이 채널 id이다.
그러나, 두번째와 세번째 url에서는 채널 id를 알아낼 수가 없다.
채널의 페이지 소스를 보면 아래와 같이 meta 태그에서 채널 id를 알아 낼수 있음을 알수 있다.
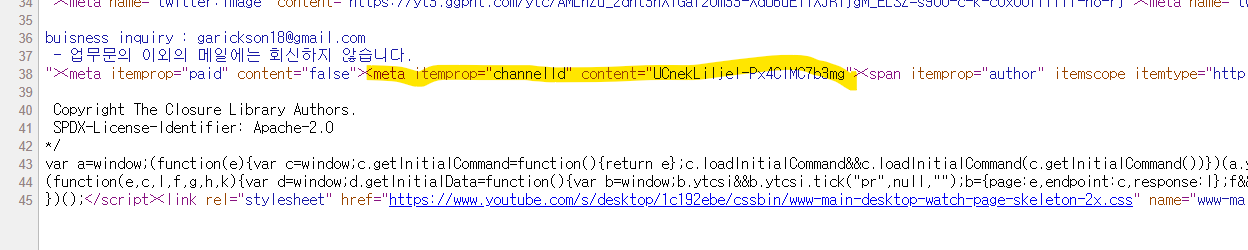
따라서 두번째와 세번째 url에서는 meta 태그를 크롤링해서 채널 id를 알아낼 것이다.
코드는 다음과 같다.
def get_channel_id(value):
# print(value)
query = urlparse(value)
if query.hostname in ('www.youtube.com', 'youtube.com'):
if query.path[:9] == '/channel/':
return query.path.split('/')[2]
else:
html = urlopen(value)
bsObject = BeautifulSoup(html, "html.parser")
return bsObject.find("meta",{"itemprop":"channelId"}).get('content')
# fail?
return None2-1. youtube data api 이용하여 video id 크롤링
Search를 이용하여 video id를 크롤링 할것이다.
Search에 대해서는 다음의 링크를 보면 된다.
https://developers.google.com/youtube/v3/docs/search/list
Search: list | YouTube Data API | Google Developers
Search: list API 요청에 지정된 쿼리 매개변수와 일치하는 검색결과의 모음을 반환합니다. 기본적으로 검색결과의 집합은 쿼리 매개변수와 일치하는 video, channel, playlist 리소스를 식별하지만, 특정
developers.google.com
채널 id를 가지고 특정 시점이후의 비디오 id들을 받아올 것이기 때문에 다음과 같이 작성했다.
#service => connetion to youtube data api
def get_videos(service, channel_id,date):
try:
response = service.search().list(
part="id", #응답 받을 내용들
channelId = channel_id,
maxResults=50, #최대개수
order="date", #날짜순으로 정렬
type="video", #찾는 것이 video
publishedAfter=date #특정 시점 이후
).execute()
return response['items']
except HttpError as e:
errMsg = json.loads(e.content)
print('HTTP Error:')
print(errMsg['error']['message'])
문제점 발생
https://developers.google.com/youtube/v3/determine_quota_cost
YouTube Data API (v3) - Quota Calculator | Google Developers
YouTube Data API (v3) - Quota Calculator The table below shows the quota cost for calling each API method. All API requests, including invalid requests, incur a quota cost of at least one point. The following two points are worth calling out as they both a
developers.google.com
위 링크에서 볼수 있듯이 Search는 엄청 비싸다
무료 할당량은 10000 credit이고 이전에 사용했던 video.list는 1credit이다.
그러나 Search.list 는 100credit이다. 따라서 하루에 100개의 채널에 대해서만 검색을 해볼수 있다. 그러므로 많이 사용할 수 없다.
다른 방법을 찾아보니 stackoverflow에 좋은 글이 있다.
YouTube API to fetch all videos on a channel
We need a video list by channel name of YouTube (using the API). We can get a channel list (only channel name) by using the below API: https://gdata.youtube.com/feeds/api/channels?v=2&q=tendu...
stackoverflow.com
유튜브를 업로드하면 uploads 플레이리스트에 들어가게 된다.
uploads 플레이리스트에서 동영상을 가져오는것이다.
따라서 playlistItems를 이용하여 uploads 플레이리스트의 동영상을 가져올 것이다.
2-2. playlistItems를 이용하여 동영상 크롤링
playlistItems는 재생목록과 관련된 동영상들을 리턴해준다.
자세한 것은 아래 링크에서 확인할 수 있다.
https://developers.google.com/youtube/v3/docs/playlistItems
PlaylistItems | YouTube Data API | Google Developers
PlaylistItems playlistItem 리소스는 재생목록에 포함된 동영상과 같은 다른 리소스를 식별합니다. 또한 playlistItem 리소스에는 재생목록에서 리소스가 사용되는 방식과 관련하여 포함된 리소스에 대한
developers.google.com
업로드 플레이리스트 id를 알아야 동영상들을 가져올 수 있다.
이는 youtube data api의 channel를 이용해도 된다.
그러나, upload 플레이리스트 id는 채널 id에서 첫번째, 두번째 문자만 바꾸면 된다.
채널 id는 UC로 시작하나 업로드 플레이리스트 id는 UU로 시작하므로 문자하나만 바꿔주면 id를 알아낼 수 있다.
upload 플레이리스트의 id를 이용하여 다음과 같이 작성할수 있다.
def get_videos(service, upload_id):
try:
response = service.playlistItems().list(
part="snippet", #응답 받을 내용들
playlistId = upload_id,
maxResults=5,
).execute()
# pprint(response)
return response['items']
except HttpError as e:
errMsg = json.loads(e.content)
print('HTTP Error:')
print(errMsg['error']['message'])
그러나 우리는 특정시점 이후의 동영상을 가져와야 한다.
이는 snippet의 publishedAt과 datetime 모듈을 이용하여 비교하면 된다.
3. 구글 스프레드시트에서 크롤링
구글 스프레드시트에 있는 채널 주소들을 가져와야한다.
이전 포스트에서는 엑셀에서 크롤링 했다면 이번에는 구글 스프레드시트에서 바로 크롤링 해볼것이다.
첫번째 열에만 링크들이 작성되어 있어서 첫번째 열만 받아오면 된다.
def get_link():
scope = [
"https://spreadsheets.google.com/feeds",
"https://www.googleapis.com/auth/drive",
]
json_key_path = "./momof_json.json" # JSON Key File Path
credential = ServiceAccountCredentials.from_json_keyfile_name(json_key_path, scope)
gc = gspread.authorize(credential)
spreadsheet_key = "스프레드시트 키"
doc = gc.open_by_key(spreadsheet_key)
sheet = doc.worksheet("시트1")
column_data = sheet.col_values(1)
print(column_data)
return column_data
다음 링크를 참고하여 작성했다.
https://jsikim1.tistory.com/205
Python에서 Google Sheets 를 API를 통해 사용하는 방법
Python에서 Google Sheets 를 API를 통해 사용하는 방법 Python에서 Google Sheets 를 API를 통해 사용하는 방법을 알려드리도록 하겠습니다. 1. Google Coloud Platform API Setting 1-1. Google Cloud Platform..
jsikim1.tistory.com
문제점
pyinstaller를 이용하여 exe 파일을 만들때 json파일은 제외되고 만들어지는것을 알 수 있었다.
이는 다음 링크를 통해 해결 했다.
https://stackoverflow.com/questions/57122622/how-to-include-json-in-executable-file-by-pyinstaller
How to include json in executable file by pyinstaller
Tried to build specs.spec file with the following, to include a JSON file within the executable file. block_cipher = None added_files = [ ( 'configREs.json', '.'), # Loads the '' file f...
stackoverflow.com