
AWS Well-Architected Framework
시스템 설계, 구축, 운영 과정에 활용하기 위한 AWS가 제시하는 모범 사례로서 아키텍처 설계, 구축 과정에서 결정이 필요할 때 활용하는 6가지 요소

운영효율성 - 배포 시간을 줄이는 방법
안정성 - 어떻게 빠르게 복구할건지
성능 효율성 - 변화에 민첩하게 적응
비용 최적화 - 리소스가 서비스를 구성하는데 비용을 줄이는 방안
지속가능성 - 설계할 때 클라우드를 이용하여 탄소배출 감소
한 명의 사용자를 지원하는 시스템에서 수백만의 사용자를 위한 시스템까지 확장하는 과정
가상 면접 사례로 배우는 대규모 시스템 설계 기초 1장
1. 단일 서버 환경에 구성된 소규모 고객 시스템
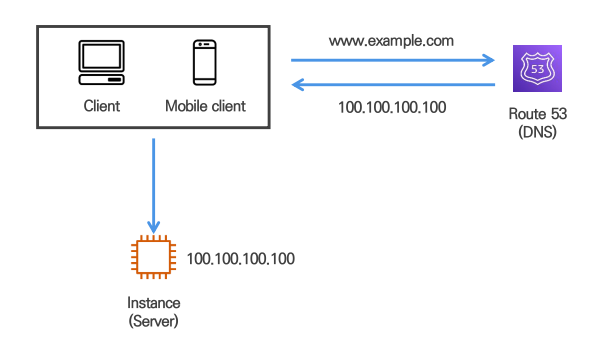
WEB, WAS, DB 모두 단일 서버에 구성
도메인 관리를 위한 DNS 서비스 이용
route53이 DNS 역할을 한다.
client가 www.example.com이라고 브라우저에 보내면 Route53이 IP를 보내주고 이를 통해 IP로 SERVER에 접속
2. 서비스 규모 확장에 따른 데이터베이스 분리

사용자가 늘고, 다루는 데이터가 많아질 경우 DB 분리 구성
✔사용자가 늘었을 경우에는 트래픽이 많아져 웹서버와 DB를 분리하여 두어야 한다.
✔단일 서버내에 데이터베이스가 있을 때 Client가 데이터베이스에 접속할 수 있다. 따라서, 보안문제로 인해 데이터베이스를 공인 IP가 없는 Private Subnet으로 옮겨야 한다.
web, was 서버 => CPU를 bound한 서버
db => I/O bound한 서버 => 메모리를 잡아먹는 경우가 많다 => 매우 비효율적이다 => 서버 스펙을 결정할때 비용적으로 손해보는 경우가 많다
3. 수직적 규모 확장 & 수평적 규모 확장
수직적 규모 확장 (Scale Up)
- 스펙 늘리기
- 서버 유입 트래픽이 절대적으로 적은 경우
- 치명적인 단점 : 물리자원(CPU, Memory..) 유한성, SPOF
SPOF : 시스템 구성 요소 중에서, 동작하지 않으면 전체 시스템이 중단되는 요소
수평적 규모 확장 (Scale Out)
- 서버 계속 복사하기
- 대규모 시스템 규모 확장에 적합
- 적당한 수직적 규모 확장이 뒷받침 된 환경에서 진행
- 로드밸런서 활용하여 이점 극대화 (보안, 확장 유연성 등)
어느정도의 사용자를 커버할때까지 수직적 확장이 이루어지고 그 뒤로는 수평적 확장이 이루어진다
기본적으로 스펙이 갖추어지고 그 후에 서버 여러대를 놓는 것이 좋다
로드밸런서
- 부하분산
- load balancer에 서버를 mapping하면 쉽게 scale out 가능(이전에는 proxy server를 앞에 두어 scale out을 함)
- load balancer가 public에 있으면 서버를 private으로 옮겨 사용 가능
- fail over 해소
- 특정 서버에서 문제가 발생하면 로드밸런서는 해당 서버로의 트래픽을 차단하고 다른 서버로 트래픽을 몰아줌으로써 고가용성을 확보할 수 있다
데이터베이스의 이중화
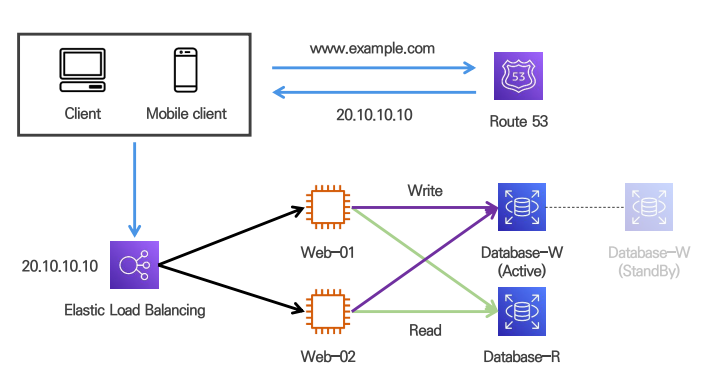
DBMS 자체 Utility & AWS 완전관리형 서비스 활용
WRITE DB & READ DB 1 vs N 형태로 구성 (Source-Replica(구. Master-Slave) 구조)
Active-Standby 를 두어 failover 때 대체할 수 있도록한다.
if) active-active가 될 경우 -> 동기화를 하지 못한다.
cf) 대부분의 애플리케이션은 Write 보다 Read 연산의 비중이 훨씬 크다.
다중화를 통해 서버 트래픽의 부하에 따라 Replica 서버 구축이 가능하다.
cf) DB서버(RDBMS)는 주로 scale up을 한다
=> 스펙을 최대로 up하게 된다면 scale up을 더이상 하지 못한다
=> 그래서 read replica를 만든다 -> only read만 가능하고 주기적으로 read replica를 update한다 (실시간 동기화는 기술적으로 불가능)
ex) 배치를 위한 read replica를 만든다
배치를 할때 다른 replica를 하나 더 만들어서 read를 replica에 접근하도록 만든다
배치를 안할때는 원본으로 접근하도록 한다.
4. 데이터베이스 성능 향상을 위한 캐시 전략
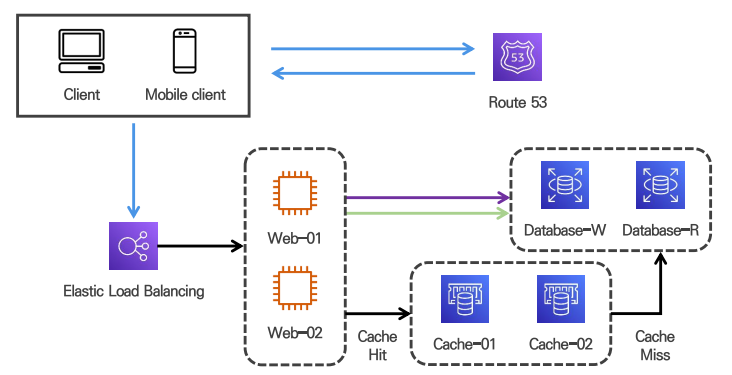
갱신 횟수가 적은 데이터는 캐시 서버 활용
SPOF 회피를 위해 캐시 서버도 이중화
캐시 서버를 한 대만 두는 경우 해당 서버는 단일 장애 지점(SPOF)이 되어 버릴 수 있다.
캐시는 메모리에 들어가 있다 -> I/O 작업 횟수를 작게 만들어준다.
cache hit일 경우 cache가 바로 데이터를 준다
cache miss일경우 db로 부터 가져오고 캐시에 넣고 데이터를 준다 -> db 접근을 줄일 수 있도록
cf) 데이터 동기화가 필요할 때 Redis에서 공동으로 사용하는 것을 넣고 사용한다
캐시는 갱신은 자주 일어나지 않지만 참조는 빈번하게 일어난다면 고려해볼만 하다.
영속적으로 보관할 데이터를 캐시에 두는 것은 바람직하지 않다.
캐시는 데이터를 휘발성 메모리에 두기 때문에, 캐시 서버가 재시작되면 모든 데이터는 사라진다.
만료된 데이터는 캐시에서 삭제되어야 한다.만료 기한에 대한 정책을 마련하는 것이 좋다.
만료 기한이 너무 짧으면, 데이터베이스를 너무 자주 읽게 되며, 너무 길면 원본과 차이가 날 가능성이 높아진다.
데이터 저장소의 원본과 캐시 내의 사본 일관성을 확인해야 한다.
캐시 메모리 크기는 너무 크지도 작지도 않게 적절하게 잡아야 한다.
캐시가 꽉 차버리면 LRU, LFU, FIFO 같은 정책들을 사용해서 사용해야 한다.
5. 애플리케이션 성능 향상을 위한 캐시 전략
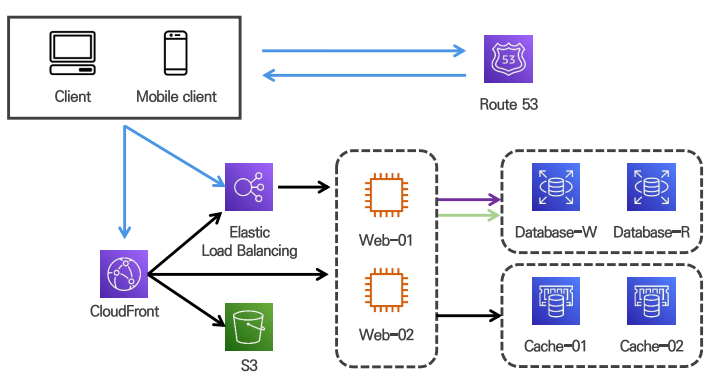
CloudFront(CDN) 캐시 서비스 활용
데이터 관리 전략을 세워 콘텐츠 무효화 전략 수립 필요
CDN : cache hit -> 바로 반환
cache miss -> elb에 접근해서 데이터 가져와서 저장하고 반환
CDN
정적 콘텐츠를 캐싱해두고 전송하는 데 쓰이는, 지리적으로 분산된 서버의 네트워크이다.
이미지, 비디오, CSS, Javascript 파일 등을 캐시할 수 있다.
CDN 은 사용자가 웹사이트에 방문하면, 그 사용자에게 가장 가까운 CDN 서버가 정적 콘텐츠를 전달한다.
만약 사용자에게 필요한 정적 콘텐츠가 CDN에 없다면 서버에 요청하여 가져온 다음, CDN에 적재하여 다음 요청부터는 CDN을 통해서 정적 콘텐츠를 제공받을 수 있다.
콘텐츠 업데이트를 위해 CDN에 저장된 콘텐츠를 무효화 시키고 싶다면 아래와 같은 방법으로 제거할 수 있다.
CDN 서비스 사업자가 제공하는 API를 이용하여 콘텐츠 무효화컨텐츠의 다른 버전을 서비스하도록 오브젝트 버저닝(object versioning)을 이용
6. Stateless Web Layer 구성을 통한 확장성 확보
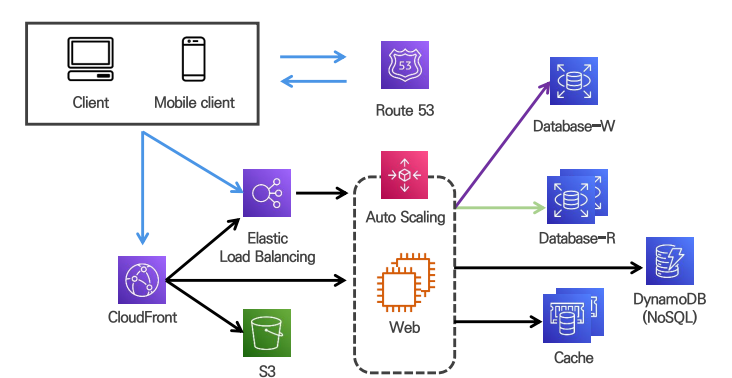
상태 정보 저장은 RDB, Cache, NoSQL 모두 가능
HTTP는 stateless하기 때문에 세션 정보를 저장해야 하는데 이를 RDB, Cache, NoSQL와 같은 외부 저장소에 저장한다.
sticky session을 이용하면 session 정보를 서버에 저장한다.
load balancer가 처음 접속한 서버로 요청 처리를 지속한다.
무상태 Stateless
클라이언트와 서버 관계에서 서버가 클라이언트의 상태를 보존하지 않음을 의미한다.
브라우저가 데이터를 전송할 때마다 연결하고 바로 끊어버리는 방식이다.
Stateless 구조에서 server는 단순히 요청이 오면 응답을 보내는 역할만 수행하며, 세션 관리는 client에게 책임이 있다. 따라서 이러한 Stateless 구조는 client와의 세션 정보를 기억할 필요가 없으므로, 이러한 정보를 서버에 저장하지 않는다.
대신 필요에 따라 외부 DB에 저장하여 관리 할 수 있다.
장점 : 서버의 확장성이 높기 때문에 대량의 트래픽 발생 시에도 대처를 수월하게 할 수 있다.
단점 : 클라이언트의 요청에 상대적으로 Stateful 보다 더 많은 데이터가 소모된다. (매번 요청할때마다 자신의 부가정보를 줘야 하니까)
상태유지 Stateful
상태 유지라 함은 클라이언트와 서버 관계에서 서버가 클라이언트의 상태를 보존함을 의미한다.
클라이언트의 이전 요청이 서버에 전달되었을 때, 클라이언트의 다음 요청이 이전 요청과 관계가 이어지는 것을 의미한다.
웹서버가 사용자(브라우저)의 상태 client(쿠기) or server(세션) 정보를 기억하고 있다가 유용한 정보로써 활용한다는 의미한다.
클라이언트에서 다른 클라이언트로, 또는 서버에서 특정 클라이언트로 메시지를 전송할 수 있다.
서버에서 클라이언트 세션을 유지할 필요가 없을 때 서버 리소스를 절약하는 장점이 있다.
Stateful 방식은 하나의 서버가 1만 명의 클라이언트를 처리할 능력이 있을 때 그보다 많은 수의 클라이언트가 몰리면, 이미 연결된 1만 명의 클라이언트 중 일부가 빠져야 다음 클라이언트가 처리된다.
하지만 Stateless 방식은 순간 접속 요청 인원을 기준으로 하므로 많은 클라이언트가 몰려도 할당된 처리량이 끝나면 다음 처리가 가능하다.
7. 데이터 센터 이중화를 통한 가용성, 접근성 확장
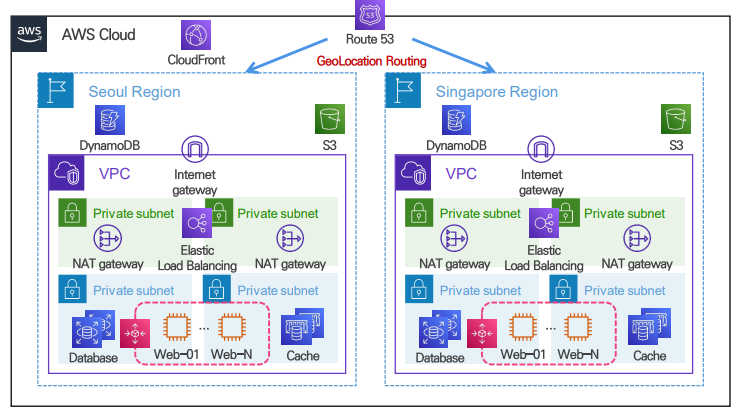
전 세계 사용자 대상 서비스로 확장 시 데이터 센터 이중화(장애 상황에 대비하기 위해) => 여러 리전에 대해 동일하게 구축
근접 지역으로 트래픽이 전달되며 접근성, 성능 향상
데이터 센터 장애 시 다른 데이터 센터를 통해 가용성 향상
Availability Zone을 통해 지역별 시스템 가용성 확보
현재 그림에서는 route53이 리전에 대해 분산하는 역할을 하고 있다
가용성 향상 : 하나의 데이터 센터 죽어도 다른 데이터 센터가 가동하고 있음
성능 향상 : network traffic latency가 작아진다
다중 데이터센터를 만들기 위해서 고려해야 할 조건
트래픽 우회: 올바른 데이터 센터로 트래픽을 보내는 효과적인 방법을 찾아야 합니다.
데이터 동기화: 데이터 센터마다 별도의 데이터베이스를 다중화하기
테스트와 배포: 여러 위치에서 애플리케이션을 테스트 해보고, 자동화 배포가 모든 데이터 센터에 동일하게 설치되도록 하는 것이 중요합니다.
8. 서비스 결합도를 낮추기 위한 메시지 큐 활용
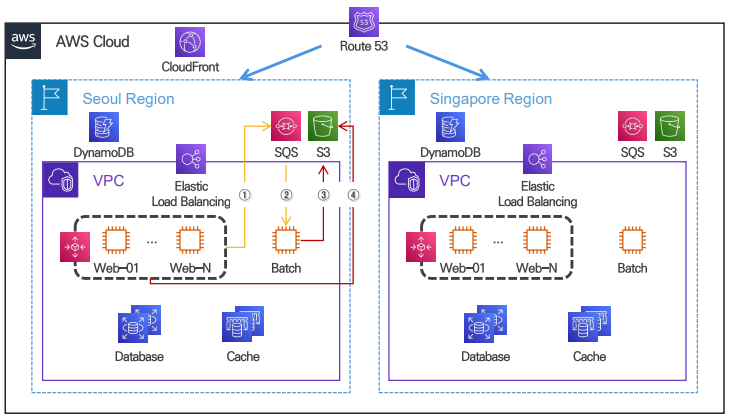
리소스 소모가 큰 프로세스를 비동기 방식으로 처리
메시지 생산자, 소비자 장애 발생에도 이어서 작업 가능
① 메시지 발행 ② 메시지 소비 ③ 처리결과 입력 ④ 결과 조회
(Publish/Producer는 메세지 큐에 발행한다. 큐에는 보통 Consumer/Subscribe가 메세지를 꺼내서 동작을 수행한다.
메세지 큐를 이용하면 서비스 또는 서버 간 결합이 느슨해져서, 규모 확장성이 보장되어야 하는 안정적 애플리케이션을 구성하기 좋다.)
비동기 방식 : 요청과 결과가 동시에 일어나지 않는 방식으로 요청과 결과가 동시에 일어나지 않는다.
9. 로그 수집, 모니터링, 자동화 도구 도입
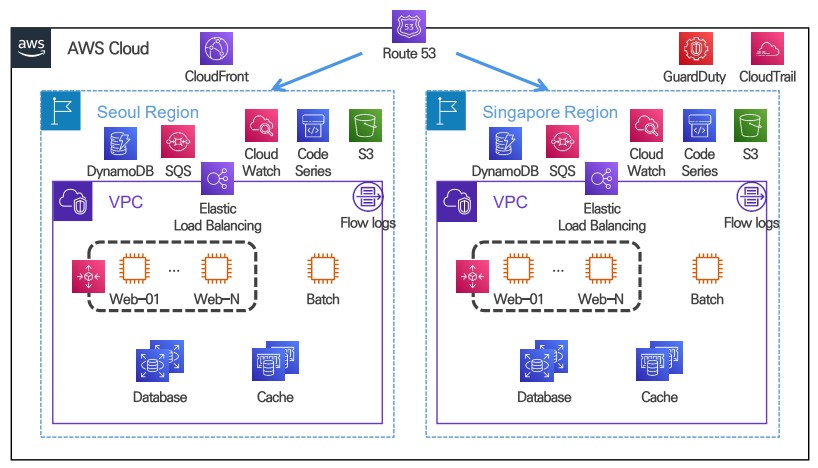
운영 관리 효율, 장애 대응 자동화를 위한 도구 도입
시스템 개발 환경의 분류
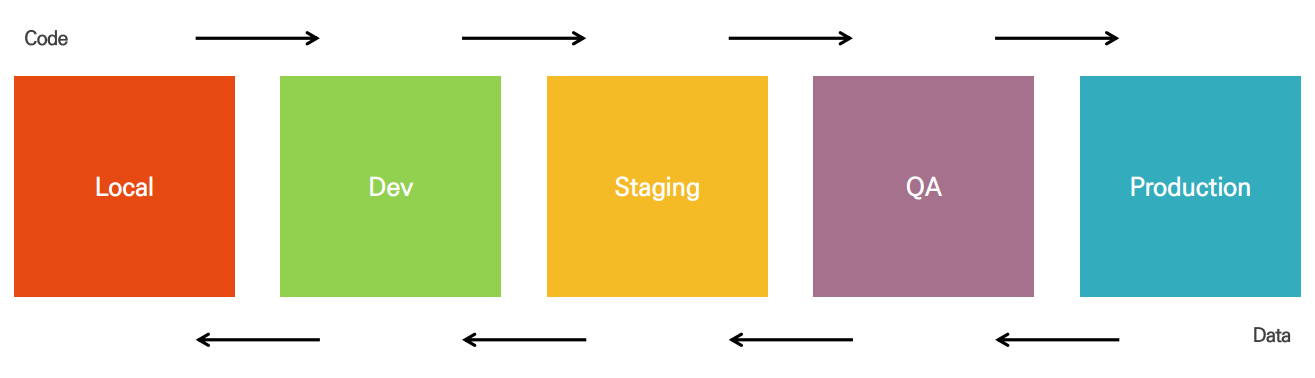
- Production : 서비스가 돌아가고 있는 환경
- QA : 품질 팀에서 서비스 품질 테스트 (서비스 동작에 문제가 없는지, 성능이 좋은지)
- Staging : Production 환경이랑 100% 동일하게 구성 (실제 환경에서 잘 동작하는지 테스트)
- Dev : 기능적 테스트를 위한 환경
- Local : 개발자 노트북
리소스 네이밍 방식 : kebab-case
